
多年來,IT 監控以各種方式被應用和部署。其核心目的是收集有關不只是 IT 基礎設施以及雲原生服務的硬體和軟體運作指標,確保所有關鍵功能都能順利運作,進而維護應用程式和 IT 服務的品質。
近年來,「可觀測性」這一術語越來越受到關注,被視為是「新一代的監控」。接下來,我們將探討什麼是可觀測性、它與傳統監控的差異,以及實施可觀測性所需的關鍵元素。
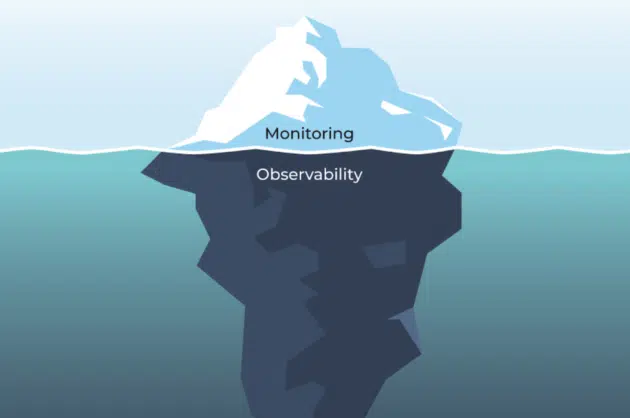
有人說:喔!可觀測性的出現只是為了應付 RD 們對於監控的厭倦而另外包裝出來的漂亮糖衣,就像原本的 Ops 又延伸出 DevOps 甚至 DevSecOps 等新潮名詞,直到榨乾我們最後一絲腦力。
在各種行業中特別是軟體業,隨著網路的活絡以及科技日益越進,每天都有推層出新的概念以及名詞出現。久而久之,大夥對於聽到新事物時,反而第一時間都是習以為常的半開玩笑,戲謔的口吻說著學不動了,但滑鼠依然不受控制地打開 Github 查看文件。
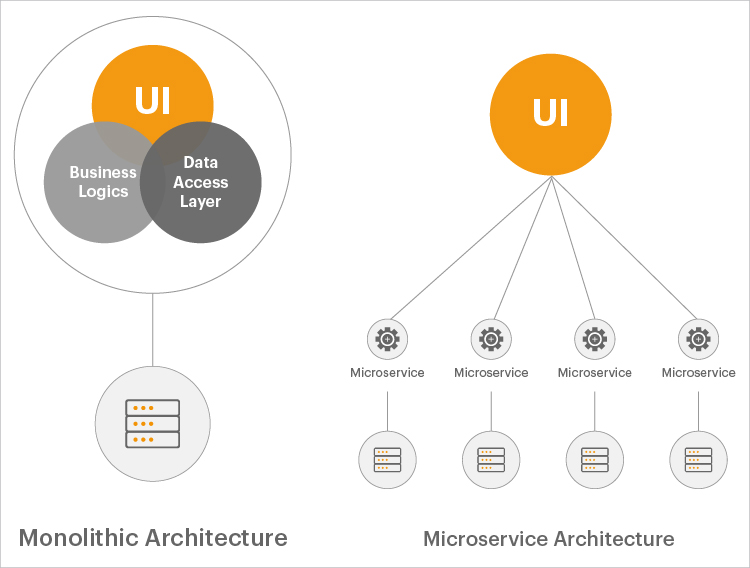
在過去二十年中,監控是工程師的職責,對於許多從事這行業許久的人,總多少代表著些不太愉快的回憶,但因為當時傳統的系統架構通常使用單體式服務和一種語言建構而成,複雜度不大且版本迭代可能數個月才會發佈一次。
而現在應用服務與傳統應用服務有很大的不同。不止是單體式與微服務的差別,使用容器、Kubernetes 等雲原生技術與多種程式語言,編排成一個完整的複雜服務。並且擁抱更多的自動化像是 Infrastructure as Code(IaC)以及其他編排機制下的自動部署,再加上 DevOps 的技術文化成熟,帶來更輕量更頻繁的迭代頻率,這其中除了系統的複雜交互溝通,更考驗多個部門團隊的協作能力。
雖然現代應用技術提供了我們敏捷性、可擴展性的彈性,並允許快速導入或修正錯誤的能力,但他們明顯增加了複雜性,帶來非常沉重的業務邏輯跟維護成本。有鑒於現代應用服務對於當今企業的重要性,每次發生故障導致服務異常,可能就會對企業帶來數十萬的收入損失。因此,人們開始意識到這個問題的嚴重並紛紛開始提出解決方案,不止要知道何時出現問題,還必須能快速定位問題原因,並且迅速反應修正,這才有後來我們耳熟能詳的『可觀測性 Observability』的誕生。
在權威機構 DORA(DevOps Research and Assessment)的研究定義了以下術語:
簡單來說,監控可以告訴你什麼時候出現了問題,而可觀測性可以告訴你為什麼出現問題。
雖然監控僅限於在 IT 系統中發生性能、使用或可用性變化(即發生異常)時通知您,但可觀察性提供了必要的詳細信息,讓您了解發生此變化的原因。思考差異的一種方法是將監控視為收集指標,將可觀察性視為提供分析收集的指標並確定需要採取哪些行動來緩解問題所需的情報和分析。
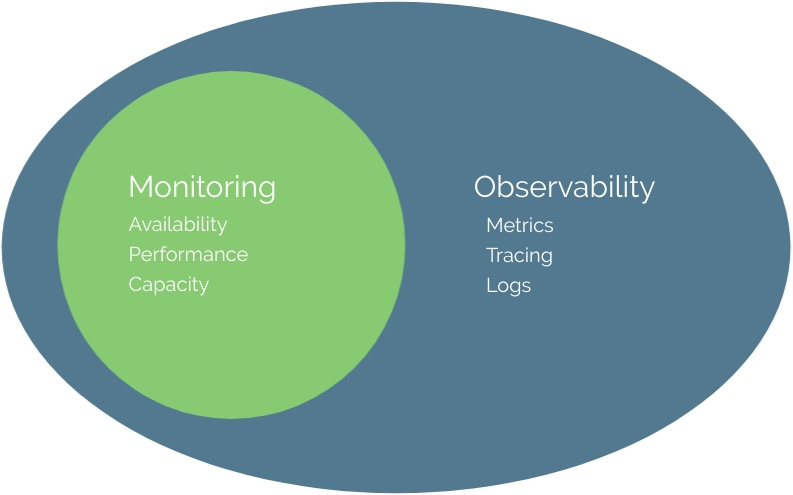
在監控方面通常從三個層面來衡量:
其中應用服務的指標通常是三者中變化最大也是最重要的,儘管傳統的監控服務已經證明,他們依然非常完善健全,但依然得隨著時代的腳步前進。
而大部分的人認為可觀測性仰賴著三種指標,以幫助我們實現可視化:
Metrics、Logs、Traces 通常被人稱之為可觀測性三本柱,這些數據類型在雲原生可觀測性上發揮著至關重要的作用,每個支柱都提供了組織資源的不同視角。當這些數據源重新被組合和分析可視化時,團隊就可以一窺複雜的應用服務中發生的情況。
監控最適合報告系統的整體健康狀況。旨在『監控一切』可能被證明是一種反模式。因此,監控最好僅限於源自基於時間序列的儀器、已知故障模式以及關鍵業務和系統指標。另一方面,“可觀察性”旨在提供對系統行為的高度精細的洞察以及豐富的上下文,非常適合除錯目的。
由於仍然不可能預測系統可能遇到的每種故障模式或預測系統可能出現故障的每種可能方式,因此我們構建可以根據證據而不是猜測進行調試的系統變得很重要。
在 2025 年的當下,現實世界中的複雜度已經進一步的提升,僅僅將遙測訊號簡單歸類成,與其再背一次 Metrics、Logs、Traces,不如用幾個實務維度來對齊 2025 的落地思維:
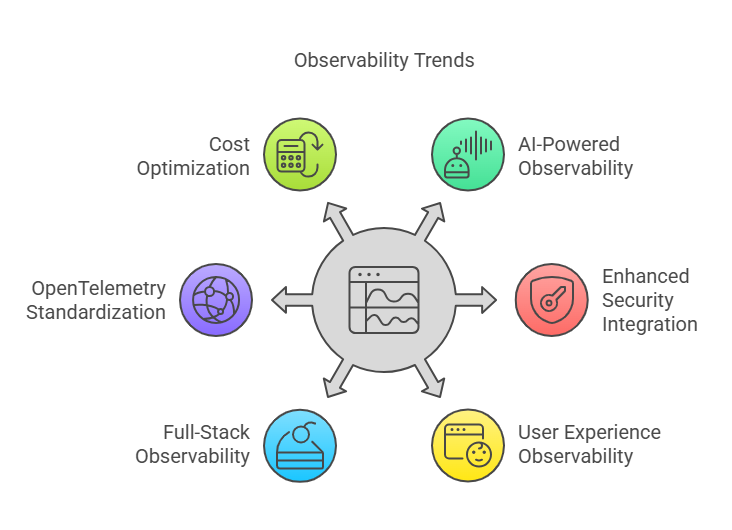
在數位系統日益複雜、多變的今日,可觀測性不再只是 DevOps 工程師的議題,而是橫跨安全、體驗與營運決策的核心能力。以下是 2025 年觀察到的六大趨勢:
AI 與機器學習技術持續深入可觀測性平台,從異常偵測、事件關聯分析,進一步擴展到自動化的根因推論(RCA)與修復建議。
然而,這些系統的準確度極度依賴資料的完整性與上下文豐富度。若僅依賴片段資訊,將可能加速「錯誤結論的自動化」,造成反效果。因此,導入 AIOps 的重點不只是模型能力,而在於資料治理與跨層級語意的統一。
安全與可觀測性逐漸融合,形成「Security-as-Telemetry」的實踐方向。具體而言,包括:
後端 200 OK 並不代表使用者真的獲得良好體驗。UXO 主張:
以 eBPF(Extended Berkeley Packet Filter) 為代表的技術,使我們得以在作業系統核心層面,低開銷地收集高解析度訊號,例如:
網路流量與封包路徑
系統呼叫與延遲熱點分析
容器間通訊與服務邊界追蹤
這類訊號能補上傳統 APM 無法觸及的「黑盒區域」,為多雲、微服務與零信任架構下的可觀測性打開新視野。
OpenTelemetry 已逐漸成為可觀測性的事實標準語言,不僅帶來 vendor-neutral 的優勢,更賦予團隊:
在不同資料來源與語言間統一 schema 與語意(semantic conventions)
透過 Collector 自由路由資料至多種後端(如 Prometheus、Loki、Datadog 等)
這種標準化降低了切換成本、強化資料治理,也讓平台團隊能真正談成本控管與策略演進。
隨著資料量爆炸成長,可觀測性平台無法再秉持「全部都存」的心態。當代趨勢強調「用得上的資料才保留」,包括:
動態抽樣與預測性過濾:根據流量特性與異常風險動態調整樣本率
分層儲存與 TTL 設計:將熱資料與冷資料分離,節省高成本儲存資源
SLO 導向的保留策略:資料保留與重點分析圍繞服務目標(SLO)展開
這些作法讓平台在不犧牲可見度的前提下,維持經濟可行性與營運韌性。
在接觸 Kubernetes 之後,我確實經歷了一場如時代縮影般的轉變,從單體式應用走向微服務架構。這段過程讓我深刻體會到,實現相同功能,在微服務環境中的複雜度往往是單體架構的數倍;那種難度不只是開發成本,而是來自系統間協作、監控與故障排查的全面挑戰。
微服務的彈性就像一把雙面刃:用得好,整個團隊如虎添翼;用不好,則可能集體陷入地獄般的混亂。更何況,如今 GenAI 已成為現象級的技術浪潮,它一方面驅動著技術革新,另一方面也衍生出前所未有的觀測與治理問題。
但正因如此,我們更應記得:工程師的價值,就是用來解決困難的問題。
越危險的地方,往往風景越迷人。那麼,我們還有什麼理由,不全力投入這個充滿挑戰與機會的「可觀測性世界」呢?
References:

